I built a $0 lead-research agent instead of paying for a leads database
· Mick Brzeziński
- AI agents
- lead generation
- build in public
A leads database (Apollo, ZoomInfo, Crunchbase) runs $300+/month and hands you the same rows everyone else is buying. I wanted the opposite: a short, ranked list of companies that actually fit, each with a reason to reach out now and a draft I could send. So I built an agent for it instead.
One real run: 107 companies discovered → 94 read first-hand → a shortlist of 66, each with a fit score, a cited signal, and a drafted opener. Marginal cost: $0.
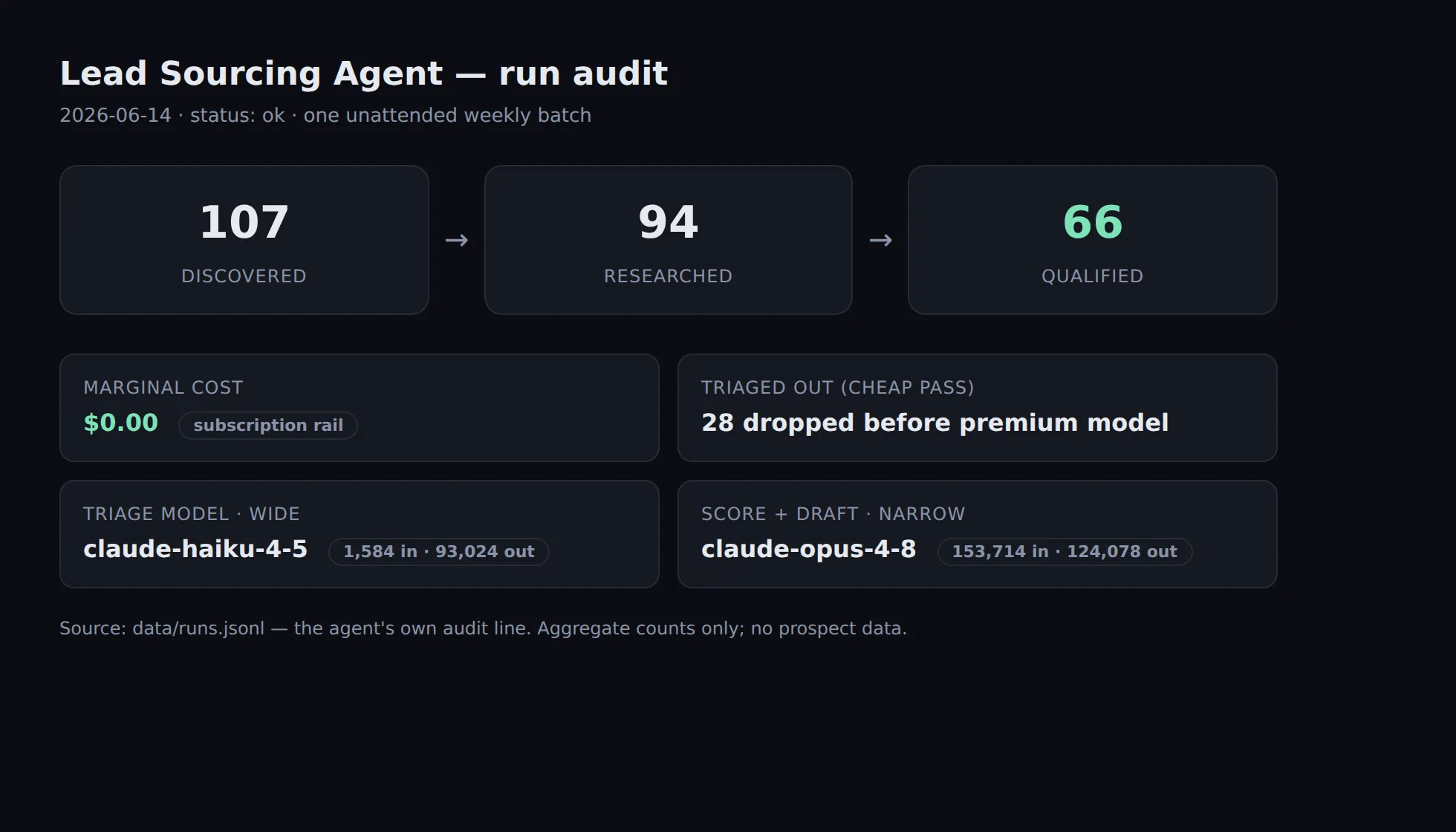
The agent’s own run audit: a cheap model (Haiku) triages the wide list; the premium one (Opus) only scores the survivors.
The pipeline runs weekly, unattended: discover → research → triage → score + draft → store, ranked. The interesting parts are five decisions behind it.
1. Free public sources instead of a paid database
Candidates come from three free, keyless places:
- Launch HN / Show HN — companies posting their own launch.
- GitHub projects gaining traction — popular repos from public search.
- The YC company list — every batch, public.
The non-obvious bit: each one links to the company’s own domain, not an aggregator profile — which is what lets the next step go read the source directly. That’s the difference between “free data” and free data you can actually act on.
2. Cheap model wide, premium model narrow
Pointing a top-tier model at 100+ companies a week would be slow and expensive, so the work splits by cost. A cheap, fast model does the wide first pass and drops the obvious non-fits (hobby repos, free OSS, wrong segment). Only the survivors reach the premium model — and even there, hard rules go first: deterministic checks in code (segment, funding stage, headcount ≤ 50) reject known mismatches before the model spends a token. What’s left, it scores against a weighted rubric and has to justify each point, so the ranking is reproducible rather than vibes — then it writes the draft.
You never pay premium rates to reject junk. Cost control is the shape of the pipeline, not a setting.
3. Cite-or-null: no made-up “congrats on the raise”
The reason AI outreach gets ignored is fabrication — a confident “congrats on your $5M round” when there was no round. One hard rule fixes it: every concrete claim in a draft must point to a page the agent actually read. No source, the field stays blank. It’s allowed to know less; it’s not allowed to make things up.
4. A ledger so it compounds instead of repeating
Every company it evaluates — shortlisted or rejected — gets logged with a date, and next week’s discovery skips it. Effort goes only to genuinely new companies. By design that makes each week cost less than the last, instead of re-grinding the same list.
5. No servers: it runs on a subscription I already pay for
The last decision is where the agent lives — and the answer is nowhere I maintain. No VPS, no cron box, no API key to rotate. The whole pipeline runs as a scheduled routine on Claude Code on the web: Anthropic’s cloud spins up a throwaway container, runs the batch unattended, commits the ranked leads back to the repo, and disappears.
The piece that makes it free is that the agent auto-detects the Claude subscription it’s already standing on. It checks for the Claude CLI; if it’s there, every model call — the cheap triage and the premium scoring alike — bills to the plan I already pay for to write code, not metered per token. (No key present? It quietly falls back to API billing, so a run never dies over plumbing.)
So the marginal cost of a 100-company run isn’t “cheap” — it’s nothing: no token bill, no machine to keep alive, no ops. The infrastructure for a weekly autonomous agent turned out to be a subscription I already had, plus a scheduler I didn’t have to build.
The best feature is the one it refuses to do
It drafts. It never sends.
A cold first message is the start of a relationship — not something I want a model firing off on my behalf. So the agent does the mechanical 80% (find, research, score, draft) and I do the 20% that needs judgement: who’s worth a real message, and what goes out under my name. The leads stay private; they’re business data, not content.
What “66 qualified” actually means
A company makes the shortlist only if it clears the cheap triage, scores at or above the fit threshold, and has at least one buying signal the agent could cite. It’s fit-qualified and ranked — not 66 deals ready to close. The value is the ordering: I work the top first; the long tail is “worth a look,” not “warm.”
What it comes down to
I built this for my own pipeline, but the shape isn’t specific to sales. The model was never the hard part — wiring it into something a team can trust was. The same approach points at any repetitive, evidence-gathering workflow: a list to qualify, an inbox to triage, a pile of docs to answer from.