A Fable 5 agent called both World Cup openers — to the exact score
· Mick Brzeziński
- AI agents
- LLM
- build in public
Before they blocked Fable, it wrote me the system that called the first two World Cup matches perfectly.
Mexico vs South Africa finished 2–0. My agent had called it 2–0 that morning. South Korea vs Czechia finished 2–1 — the agent had called 2–1.
Two opening matches of the World Cup. Two exact scorelines. In our office pool at createit.com, an exact score is worth 3 points and the winner alone is worth 1. Six out of six.
I’ve shipped software for fifteen years and build LLM agents for a living. So this isn’t “look what AI did.” It’s a teardown of why it worked — and, at the very bottom, an honest look at how it’s gone since. None of it is magic.

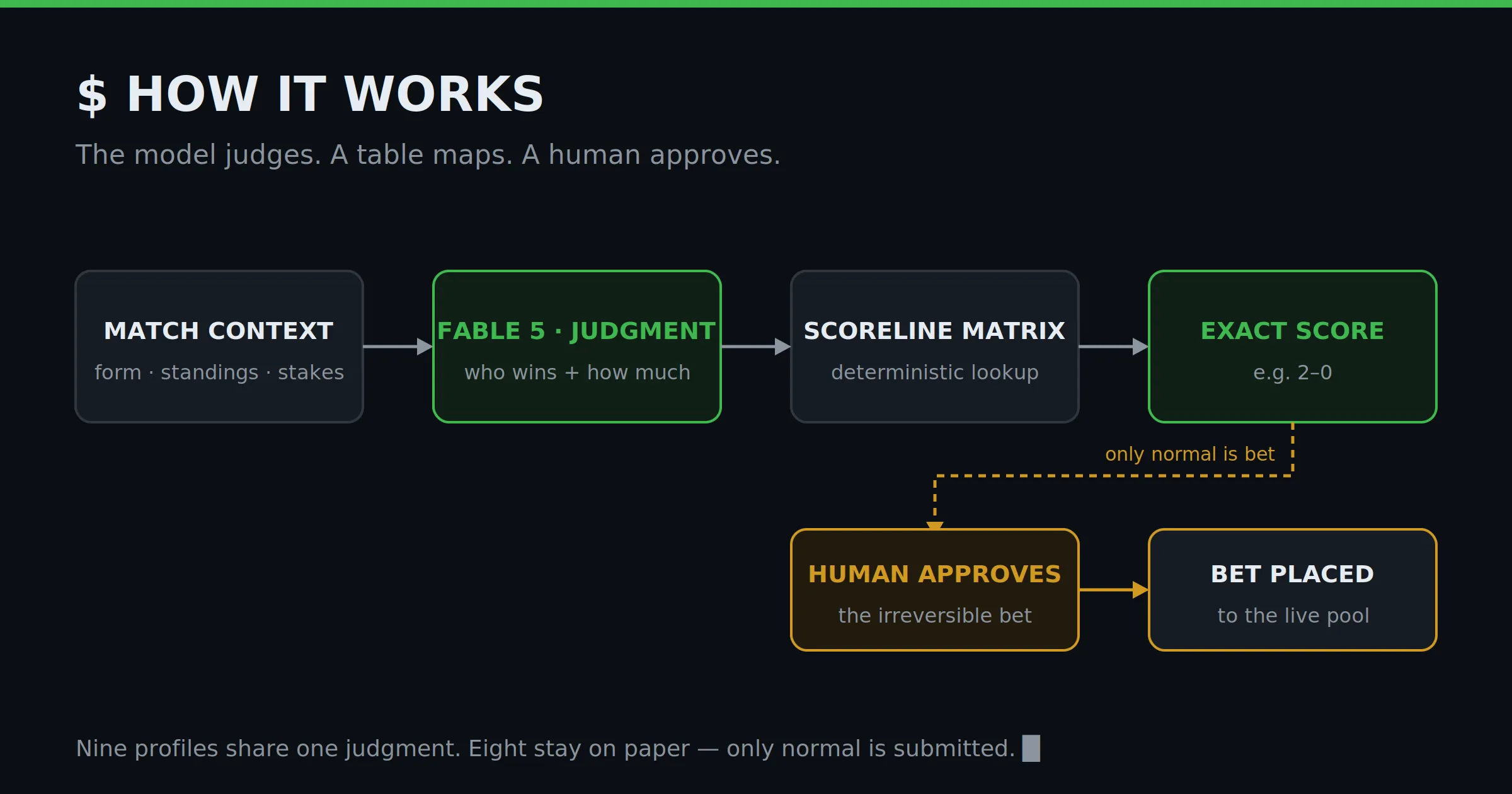
The agent does not “predict the score”
Prompt a model with “give me the score” and you get a number from its gut — untunable, untestable. So I split the question in two:
Judgment (the model’s job): who wins (home/away/draw) and by how much (slight / clear / mismatch). This is where form, the group table, and stakes get weighed — the part LLMs are actually good at.
Mapping (a deterministic matrix in code): it turns that judgment into a concrete scoreline, the same way every time. It never decides who wins — only what number the judgment maps to.
An LLM is brilliant at judgment and terrible at consistency. So I let it judge and forbade it from improvising the scoreline. Determinism is the feature.
Why you never bet 4–2
Scoring: exact = 3, winner only = 1, miss = 0. That gives one rule:
EV = 1 × P(direction) + 2 × P(exact score)Lock the direction point, then within that direction pick the most common scoreline. From the 2022 group stage: 2–0 (23%), 1–0 (19%), 2–1 (17%), 0–0 (12%), 1–1 (6%). Exotic scores almost never hit exactly, so they waste the 2-point upside. The matrix only reaches for them on a real mismatch.
Mexico, clear favourite → most likely score is 2–0. It finished 2–0. Not a guess — the top of the distribution, placed coldly. The priors are backtested on 2018 and 2022, and the matrix is cross-validated so it doesn’t overfit one tournament.
Nine agents, one bets for real
I run nine “characters.” All get the same judgment; they differ only in how aggressively they map it:
- 🛡️ safe — the floor (1–0).
- ⚖️ normal — modal scoreline by strength. The only one that bets for real.
- ⚔️ brave — chases the exact (bigger margins).
- 🤖 control — ignores strength; dumb 2–0 / 1–1 baseline.
- 📉 minimalist — always the lowest score.
- 🥅 btts — favourite wins, underdog scores (2–1 / 3–1).
- 🎯 calibrated — risk dialled by confidence.
- 🤖 agent_call / agent_free — a free-reasoning model instead of the matrix.
Eight are paper bets, scored on a file. Same judgment across all nine means character is the only variable — so at tournament’s end I won’t just know how many points I won, I’ll know which philosophy won.
The disciplined agent beats the creative one
Here’s the result I didn’t expect to enjoy this much.
Two of those nine profiles throw out the matrix entirely and let a free-reasoning model pick scores on instinct — momentum, narrative, nerve. Exactly the “just let the AI cook” approach everyone reaches for first.
It’s losing. The cautious, deterministic normal is ahead of the free-reasoning agent. The version that’s allowed to be clever is doing worse than the version I deliberately made boring. Turns out the value of an LLM here is its judgment, not its imagination — and the moment you let it freestyle the part that should be a lookup table, it gives points back. Discipline > vibes, even when the vibes come from a very good model.
Why I’m ignoring the hot start
Two perfect calls feels like a system that works. It mostly feels like that because two is a tiny number.
Twenty-four matches per round, scored 3/1/0, is loud with variance. A hot open is exactly what noise looks like before it regresses. So the rule is: re-judge every round from scratch, and do not retune the matrix off one round’s results — the real lever is judgment quality, not the table. There’s a checkpoint to re-fit it after the group stage, on this tournament’s own data, with ~72 judgments in hand. Not before. Believing your own hot streak is how you turn a good system into a curve-fit to luck.
(How loud is that variance? Scroll to the bottom. It came for me fast.)
A human pulls the trigger
A bet is irreversible. So the agent prepares the whole round, shows me the slate as a dry run, and stops. Only my explicit OK releases the real bets. The agent does the work; the human owns the one action that can’t be undone.
Under the hood
One Python file, standard library only, zero LLM calls in the code — the script is plumbing, the model is the brain, they never blur. The model’s whole output per match is one token:
1:home:clear:lean(game · who wins · how big the gap · how sure of the direction). A deterministic table maps it to nine scorelines — clear → normal 2-0, safe 1-0, brave 3-1, and so on.
The nugget I like: the calibrated profile maps confidence to risk, and it dials down, never up. Under flat 3/1/0 scoring, chasing the exact score is negative-EV however sure you are — so being confident is never a licence to gamble.
The two “creative” profiles skip the table for a frozen persona prompt — “a bold, instinct-driven bettor with ice in your veins… back your conviction with committed scorelines, return only JSON.” Per round the pipeline is just: prepare → I judge → derive → dry-run → I approve → submit → score.
Steal this
Strip out the football and the transferable pattern is just five lines:
- Split judgment from formatting. Let the LLM make the fuzzy call; don’t let it improvise the structured output.
- Make the deterministic part deterministic — a table or function in code, not a second prompt.
- Optimise for the real scoring function, not for looking smart. Write the EV down.
- Run shadow variants. One real, N on paper, same inputs — so you measure the strategy, not one lucky outcome.
- A human owns the irreversible action. The agent prepares; you approve.
So how’s it actually going
Right. About that hot start.
After going 2-for-2 on exact scores before dinner on Sunday, my agent has correctly predicted exactly zero exact scores since. Peak performance lasted roughly 180 minutes.
The full scorecard for normal, through 12 of Matchday 1’s 24 matches:
| # | Match | Call | Result | Pts |
|---|---|---|---|---|
| 1 | Mexico vs South Africa | 2–0 | 2–0 | 3 — exact ✅ |
| 2 | South Korea vs Czechia | 2–1 | 2–1 | 3 — exact ✅ |
| 4 | United States vs Paraguay | 2–1 | 4–1 | 1 — direction |
| 5 | Haiti vs Scotland | 0–2 | 0–1 | 1 — direction |
| 10 | Germany vs Curaçao | 2–0 | 7–1 | 1 — direction |
| 12 | Sweden vs Tunisia | 2–1 | 5–1 | 1 — direction |
| 3 | Canada vs Bosnia & Herzegovina | 2–1 | 1–1 | 0 |
| 6 | Australia vs Turkey | 1–2 | 2–0 | 0 |
| 7 | Brazil vs Morocco | 2–1 | 1–1 | 0 |
| 8 | Qatar vs Switzerland | 0–2 | 1–1 | 0 |
| 9 | Ivory Coast vs Ecuador | 1–1 | 1–0 | 0 |
| 11 | Netherlands vs Japan | 2–1 | 2–2 | 0 |
10 points across 12 matches. Two exact scorelines, both before 9pm Sunday. Six of twelve directions correct — a 50% hit rate, which is to say a coin would have matched my carefully engineered, backtested, cross-validated football oracle on who even wins. (It did call Germany to beat Curaçao. It did not call 7–1. In fairness, nobody called 7–1.)
The good news: normal — the only one that bets for real — is top of all nine. The free-reasoning agent is dead last. Discipline > vibes.

104 matches in the tournament, 92 to go. I’ll report the numbers as they land — including the ones that make me look like this.
Footnote, re: the title. I built this with Claude Fable 5 — public for about three days. It launched June 9; my agent called the openers June 11; on June 12 the US ordered Anthropic to cut Fable 5 off for all foreign nationals, and it was pulled worldwide within hours. I’m a Polish dev — so the model that engineered this was gone two days after it went 2-for-2. Access is fragile; the edge is knowing what to ask before someone decides you can’t.